j’apprécie borgbackup et l’utilise pour un backup local (montage de hd externe.) : c’est génial.
MAIS …
L’utiliser vous en mode pull (le serveur de sauvegarde va chercher la data sur le serveur a sauvegarder) ?
Et surtout est-ce faisable ?
Pour mon futur chatons j’ai besoin de cette features … et elle semble absente !
Nope borgbackup c’est du push: le serveur à sauvegarder envoie les données vers le serveur de sauvegarde.
Pour faire du pull avec, ce serait de la bricole avec par exemple un script qui seraient executé via ssh. Mais vu que j’ai pas compris pourquoi tu as besoin de cette feature, je ne peux répondre d’avantage.
salut, mon serveur de backup est dans une zone protégée (par isolation physique ET via parefeu 2x)
C’est lui qui va chercher la data dans la zone ouverte au « public », sur les serveurs de prod en backend. (L’inverse est bloqué par les couches osi niveau 2 et supérieur)
Donc c’est hors de question (yes!) que tout les serveurs accessibles au public puissent aller gentillement poser leur data sur ce serveur de backup qui centralise les sauvegardes de toutes la prod …
Borgbackup peut faire du pseudo pull, via SSHFS (mount local ), j’essaierai de vous faire un retour.
EDIT : Donc, comme je m’en doutais les LXC de proxmox c’est bien mais je savais que les limites niveau accès distant, syst. de fichiers etc étaient bien chiant : bingo, pile dedans, pas de fuse possible dans un conteneur LXC.
Mais proxmox , sait faire du qemu/kvm : et là on revient sur un terrain connu.
Donc ssh avec passphrase, auth. par clef … montage du file system distant avec sshFS (les perfs sont bonnes avec un cryptage soft) : donc on fait du pull-mode avec BorgBackup. ça tombe bien j’ai déjà un script qui fait tout ca clean.
sshfs Host_to_Backup:/ /mnt/BorgBackup/ (aussi simple que ca) (<Host_to_Backup> a remplacer par tout hôte à sauvegarder)
Pour vous informer que BorgBackup tourne nickel avec une rétention sur 5 ans, 12 mois , 4 semaines.
La prod est donc en lieu sure, je ne me voyais plus avancer sur cette infra. auto-héberger sans backup.
Le serveur de sauvegarde du site 1 est ok et surtout bien sécurisé car isolé de la prod. sur un réseau de sauvegarde dédié (physiquement).
Volontairement je n’ai pas cherché les snapshot et autres « complications » : pour moi la sauvegarde devant être un truc simple , robuste et crontrôlable à 100% (pas dépendre de zfs, ceph et autres techno … bien plus complexe !)
Si certains veulent les scripts (4) etc … demandez en privée.
Pour le coup j’arrive un peu après la bataille mais tu as borgmatic qui fait exactement ce que tu veut et de façon maintenue (pas besoin de faire des script maison).
Pour mon usage j’ai uniquement des sauvegardes par snapshot des conteneur/VM sous Proxmox et de l’externalisation par un stockage NFS distant.
Je fait du 7 jours glissant en local et externalisation des 2 hebdomadaires par défaut (j’adapte avec les hébergé sellons leurs besoins).
Il m’est arrivé de déployer du Backuppc en entreprise pour des serveurs comme des postes, ça juste marche après s’êtes fait 2/3 nœuds au cerveau pour la configuration du serveur et des sauvegardes. Gros avantage la WebUI qui permet de parcourir les sauvegardes et demander des restaurations globale ou de fichiers spécifique. Petit inconvénient pour ce qui est base de donnée, il faut prévoir un script (par exemple mysqldump pour MySQL/MariaDB).
cela m’intrigue :
« Pour mon usage j’ai uniquement des sauvegardes par snapshot des conteneur/VM sous Proxmox »
Peux tu détailler ?
Note : J’ai fuis les snapshot car je sais qu’un snapshot par relaché/libéré peux péter une prod en saturant les disques …
J’ai aussi eu mon époque BackupPC : une fois en place c’est bien (fouillon au niveau webgui mais juste le fait comme tut dis ;-))
En terme de compression dédup , borgbackup n’a pas d’équivalent libre (à ma connaissance), cet outil est vraiment robuste. En sshFS, plus compression , plus ceph RDB (avec des disques plateaux, ds pauvres cartes gigabit) … je backup à 15Mo/s : pour moi cela le fait !
Je vois pas l’interet de Borgmatic à part rajouter une couche et niveau secu pousser les data sur un serveur , bof bof … j’ai choisi de « planquer » mes serveurs de sauvegardes (la prod. ne peut pas les voir/atteindre : protection par commut + firewall) qui font du pull des données via un sshFS, le réseau de sauvegarde est dédié (3 noeuds avec carte gigabit vers un lien 2 Gigabit puis un noeud locale un distant en Gigabit)
J’utilise l’outils de sauvegarde de Proxmox qui s’appuis sur cron, LVM et tar (plus roots et fiable y’a ? ) pour réaliser des snapshots (si j’ai bien compris: création d’un volume temporaire pour recueillir les écritures pendant la sauvegarde par tar du filesystem, puis report des écritures).
Au final j’ai une archive du VPS, totalement portable vers un autre Proxmox (voir LXC ou Qemu/KVM mais j’ai pas testé).
Backuppc, je vois surtout l’intérêt de la webUI pour que les hébergés ai de l’autonomie dans la restauration et même la sauvegarde manuelle, mais comme tu le sais c’est pas non plus Mme Michu proof du coup je cherchais si y’avais des alternatives et je suis tombé sur borg et Borgmatic.
J’ai pas essayé encore Borgmatic à vrai dire je t’en parle par ce que j’ai juste eu le temps de feuilleté la doc avant hier, jugé le truc à priori pas trop débile (moyen de pull des sauvegarde, le push c’est pour les maso et les fou ) et de décider de m’y intéressé (je doit le tester un de ces jours quoi ).
Avez vous déjà été confronté à un souci de RAM avec BorgBackup ?
Personnellement je me demande si les perfs moyennes (sur un volume de taille correct de données , 200Go) de backup sont du à cela …
It is assuming every chunk is referenced exactly once (if you have a lot of duplicate chunks, you will have less chunks than estimated above).
It is also assuming that typical chunk size is 2^HASH_MASK_BITS (if you have a lot of files smaller than this statistical medium chunk size, you will have more chunks than estimated above, because 1 file is at least 1 chunk).
If a remote repository is used the repo index will be allocated on the remote side.
E.g. backing up a total count of 1 Mi (IEC binary prefix e.g. 2^20) files with a total size of 1TiB.
with create --chunker-params 10,23,16,4095 (custom, like borg < 1.0 or attic):
mem_usage = 2.8GiB
with create --chunker-params 19,23,21,4095 (default):
mem_usage = 0.31GiB
Note
There is also the --no-files-cache option to switch off the files cache. You’ll save some memory, but it will need to read / chunk all the files as it can not skip unmodified files then.
Non pas de mon côté, mais j’ai pas testé avec 200Go d’un seul coup. Je fais tourner ça sur du petit matos (1G de ram). A noter que mes nouvelles unités de sauvegarde seront plus costaud en ram, mais c’est pour faire des test de restauration automatique, pas spécialement pour borg…
Je trouve ce soucis étrange.
Peut être que c’est lié à l’usage de sshfs… Il me semble qu’il y avait un avertissement sur les performances induites par ce mode d’utilisation.
ben Borg n’est pas trop fait pour faire du pull mais du push … il envoie les data vers un dépôt local ou distant.
Quand tu veux faire du pull … tu passes par SSHfs pour monter le File System du serveur distant que tu veux sauvegarder … Ainsi tu n’exposes jamais tes sauvegardes à ta prod.
Et bien que disposant d’un réseau dédié à la sauvegarde (en Gigabit) je met une grosse heure pour sauvegarder 200 malheureux Go … ce que je trouve long.
J’ai observé des pics mémoires à 5.9Go pour sur mon serveur de sauvegardes ou tourne BorgBAckup.
En fait, je voulais que tu me dises, je veux faire le backup de la machine A sur la machine B et être sur que si A est compromis, A ne puisse pas supprimer B, et inversement.
Dans ce cas là, pull est une solution, mais il y en a une autre avec borg, et c’est celle qu’on utilise.
La solution est append-only Le seul truc, c’est que des fois, il faut aller nettoyer à la main les anciens backups.
Salut pierre, en fait pour l’histoire de A vers B : voici le schema pour comprendre …
Mon serveur de sauvegarde va chercher les données sur les serveurs de Prod (via un lien dédié à 2GB puis 1GB , je pourrai ainsi paralléliser des backup … mais niveau ceph et mes HDD plateau ca va tirer un peu la gueule …), ce sont des LXC (LAN)
non sérieux, va chez cquest là à mon avis on doit pleurer !!! , (cquest si tu m’entends balances ton schéma réseau , si t’es un barbu !!! )
ilinux, y’a une baie pour tout ça … une baie à 170€ … et 8 cartes mère de recup core i5 ! (en basse conso)
5 commut (200 boules les 8 … j’ai du spare) et 2 firewall recyclés en pfsense …
Tout résides dans l’architecture et les concepts sous-jacents.
Ce qui me gonfle c’est les ouatmilles failles par les applis web : c’est des nids de véroles tout ça !
Note : papote avec un des gars de 42L … ils ont fait un truc assez chiader rien qu’avec du docker !
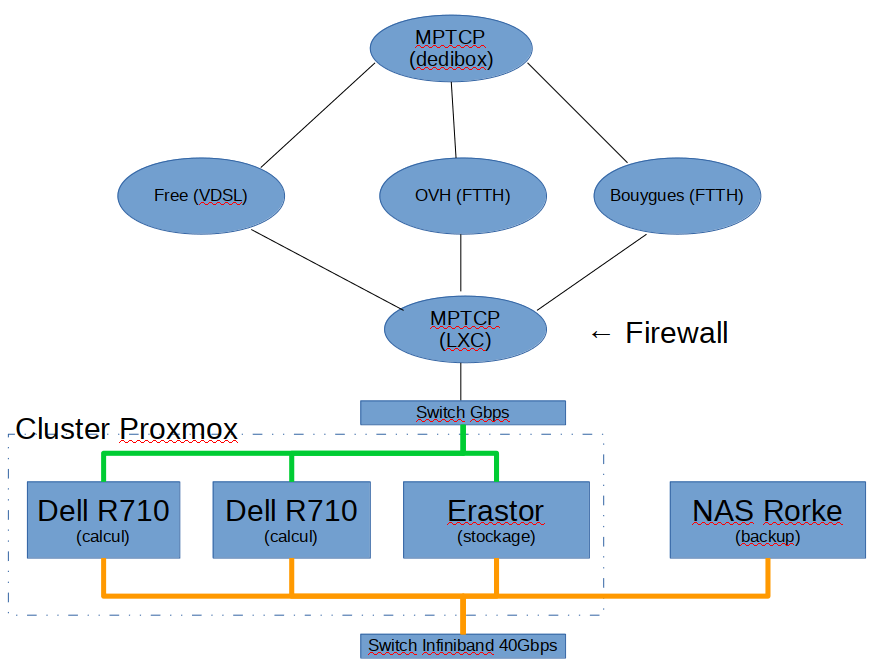
J’agrège les 3 lignes (2 FTTH et 1 VDSL) avec MPTCP Router, qui tourne dans une VM sur une dedibox et un container sur le cluster proxmox interne. Le but principal: redondance des liens et en bonus ça me sert de firewall.
Switch (avec alim redondante)… les serveurs sont tous reliés en ethernet bond (active-backup).
Second réseau « dorsal » en infiniband 40Gbps… pour les échanges internes du cluster, les synchro, backups, etc…
Bref, j’essaye d’avoir de la redondance partout. Pour l’énergie, une des deux alims de chaque serveur ou switch est sur onduleur (3kVA).
Matériel presque entièrement de récup ou d’occasion.
TROP cool !!!
J’ai eu le support de ThomasWaldmann , le dev de BorgBackup …tadadada …
quand on commmence à avoir bcp de fichiers à sauvegarder … (style de 137Go)
il faut utiliser cette option :
Résultat sans appel de 1h20mn … je redescends à … 3mn !!!
Je vais vérifier à la prochaine prod. ce soir … mais tout semble nickel.
Ca se joue là :
Backup speed is increased by not reprocessing files that are already part
of existing archives and weren’t modified. The detection of unmodified files
is done by comparing multiple file metadata values with previous values kept
in the files cache.
This comparison can operate in different modes as given by --files-cache:
ctime,size,inode (default)
mtime,size,inode (default behaviour of borg versions older than 1.1.0rc4)
ctime,size (ignore the inode number)
mtime,size (ignore the inode number)
rechunk,ctime (all files are considered modified - rechunk, cache ctime)
rechunk,mtime (all files are considered modified - rechunk, cache mtime)
disabled (disable the files cache, all files considered modified - rechunk)
**inode number: better safety, but often unstable on network filesystems**
Archive name: web3-11_12_2019:45
Archive fingerprint: 1118f99bf3c90fa37bcde9fb1c7ab90dd4da16762c3e88257b0270774416c5bf
Time (start): Wed, 2019-12-11 09:45:05
Time (end): Wed, 2019-12-11 09:48:47
Duration: 3 minutes 41.90 seconds
Number of files: 216685
Utilization of max. archive size: 0%
Original size Compressed size Deduplicated size
This archive: 137.64 GB 137.24 GB 42.15 MB
All archives: 3.44 TB 3.43 TB 144.74 GB
 ) pour réaliser des snapshots (si j’ai bien compris: création d’un volume temporaire pour recueillir les écritures pendant la sauvegarde par tar du filesystem, puis report des écritures).
) pour réaliser des snapshots (si j’ai bien compris: création d’un volume temporaire pour recueillir les écritures pendant la sauvegarde par tar du filesystem, puis report des écritures). ) et de décider de m’y intéressé (je doit le tester un de ces jours quoi
) et de décider de m’y intéressé (je doit le tester un de ces jours quoi 

 )
)