Chez ARN on essaie d’optimiser notre drbd, car nous avons constaté que parfois il y a des lenteurs sur nos VPS HDD (pour l’instant les SSD ne semblent pas en souffrir).
On a constaté que sur certains VPS parfois les io disque tombent extrêmement bas (genre j’ai fait une mesure sur un des miens à 2Mo/s…).
Ma théorie certains VPS (avec nextcloud ou peertube) consomment tous les io et privent les autres VPS HDD de leurs io. Il est possible que certains utilisent de la swap sans swapiness configuré…
Les détails
Nous avons lien ethernet 1G quasi dédié à drbd entre nos 2 machines. Il y a une ressource drbd créé par VPS (via ganeti). Pour les VPS SSD il y a du raid6 ou 5 de chaque côté. Mais pour les VPS HDD il n’y a pas de raid (juste drbd), donc 1 disque 2"5 5To dans chaque machine.
On fait actuellement tourner une dizaine de VPS HDD sur ça et environ 40 de plus en SSD.
Au niveau conf: on avait pas de resync-rate configuré, on est en drbd 8.9.
Je tente ce soir de passer en protocol B (avant on était en C).
J’ai lu la doc de drbd, mais je viens ici pour voir si certaines personnes ont de l’expérience dans ce domaine et ont des idées de ce que nous devrions vérifier et comment.
Pour info: j’ai fait une mesure du trafic sur le lien, j’ai 30Mo/s sur 110Mo/s (1 Gps). Un adminsys dans un bar m’a dit que d’un point de vue réseau on considère que le lien est full quand il est à 30%.
Comment as-tu fais la mesure du trafic ? Machine à vide ou en charge ?
Si à vide, théoriquement tu devrais avoir 100% (ou pas loin) de la capacité du lien.
C’est une production, donc le système était en charge.
Là je refais des mesures et je suis à 2% de capacité du lien… Je suppose que ça doit dépendre quand il y a des gros transferts… Hier j’ai fait un test avec 3 VPS sur lesquels j’ai la main en faisant des écritures avec dd sur les 3 et j’ai fait monter assez facilement le lien à 85%.
J’ai trouvé quelques optimisation à faire pour drbd, mais je ne suis pas sûr qu’elles sont appliquées. J’ai pas trouvé comment « ajuster/rechargé » drbd sans redémarrer (car ganeti à la main dessus). Je ne peux pas faire « drbdadm adjust all ».
Ici la conf que j’essaie d’appliquer
global {
usage-count no;
}
common {
handlers {
}
startup {
# wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb
}
options {
# cpu-mask on-no-data-accessible
}
disk {
# Je mesure un ping de 0.030ms entre les 2 machines
# https://www.linbit.com/en/drbd-sync-rate-controller/
c-plan-ahead 10;
c-max-rate 33M;
# Lower al-extents = shorter resync times at the expense of lower write performance
# Higher al-extents = improved write performance, but longer resync times
# Should be a Prime number see https://wiki.mikejung.biz/DRBD
al-extents 3833;
}
net {
protocol B;
# Il parait qu'il faut le mettre plus haut si on utilise du RAID ou des HDD !
max-buffers 8001;
max-epoch-size 8001;
}
}
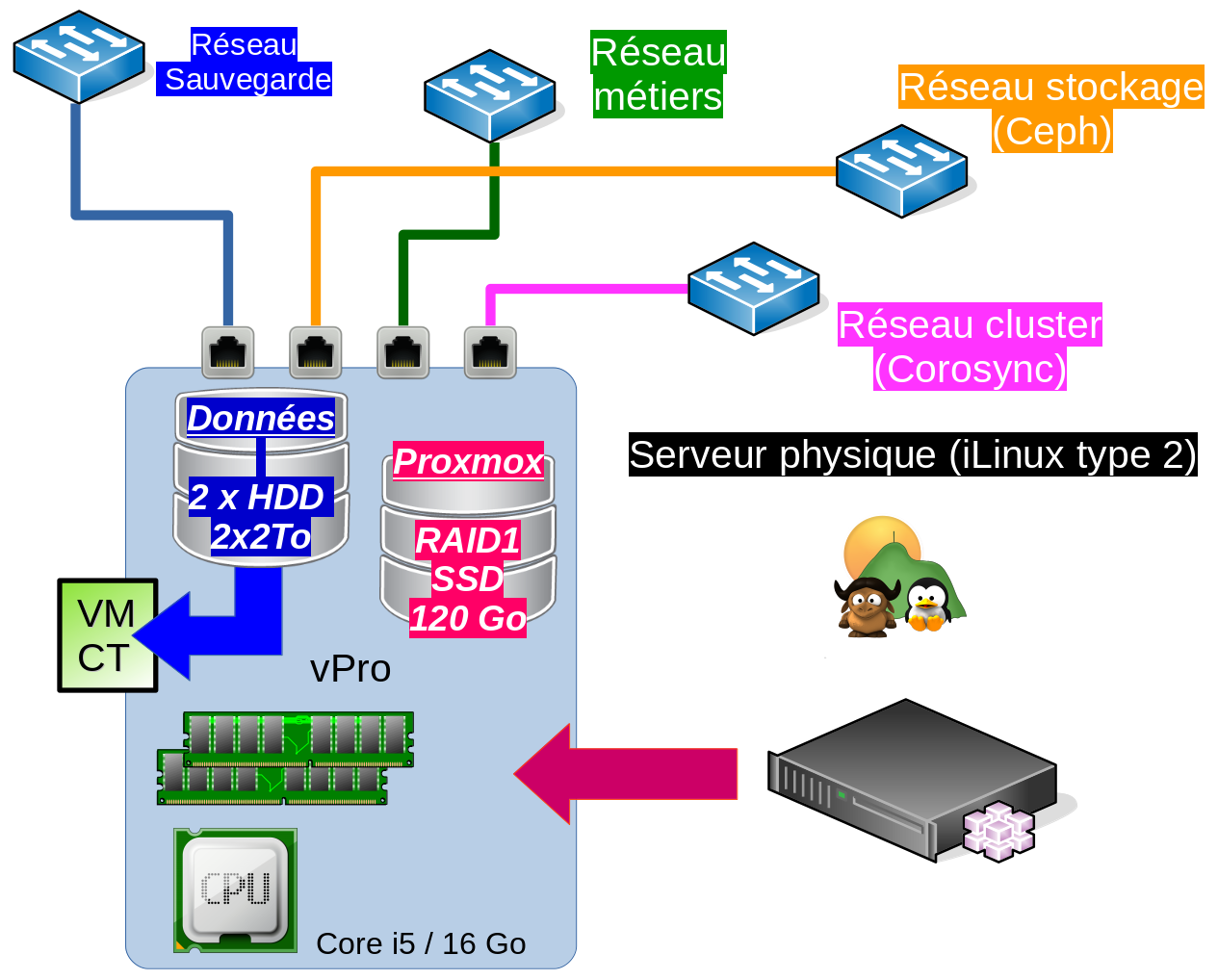
Je suis sous CEPH bluestore (rbd) pour ilinux.
J’ai pas ce genre de truc et mon matos , c’est du petit truc … comme toi de la commut 1Gb pour le stockage (en réseau distribué).
Je pose toujours la meme question : combien de carte réseau par noeuds physique ?
Ensuite quelle solution de virtu/conteneurisation utilises tu ?
As-tu bien séparé tes flux (métiers, cluster, stockage, sauvegarde) ?
(lien full à 30% ???.. lol. j’aimerai avoir l’explication , ca m’interesse l’argumenation !)
On a de la marge mais actuellement on utilise un lien ethernet direct entre les 2 machines + 2 liens ethernet vers cogent (de mémoire).
Le liens entre les 2 machines est à la fois utilisé pour BGP et pour le stockage. Mais si on veux on peut aller là bas remettre un cable supplémentaire entre les 2. La sauvegarde distante passe via cogent et pas par le lien entre les 2 machines (et de toutes façon elle est assez légère puisque c’est juste des configurations).
Au niveau virtu on est sur kvm (avec ganeti).
Pour le lien full à 30%, il m’a juste dit que c’était ce qu’on lui disait en cours de réseau à son époque (donc il y a au moins 15 ans).
Donc si je comprends bien, ton système de fichiers distribué se fait entre deux machines (physiques je suppose) via une carte réseau 1Gb TOTALEMENT dédié à cette fonction ?
Rien d’autres ne peux passer par cette carte ? (x2 puisque, une par machine) ?
Déjà si ton stockage se met à tirer à mort la gestion BGP va subir des ralentissements … (pourquoi BGP est est placé entre deux machines ? - des routeurs je comprendrai … - … n’étant pas spécialiste du protocol BGP , je n’en dirai pas plus)
La question que je repose as-tu bien séparer tes flux ? (métiers, cluster, stockage, sauvegarde)
Si oui comment ? quel répartition sur tes 2 liens ?
Un cluster doit avoir minima 4 cartes réseaux gigabit, donc 4 commutateurs Gigabit eux aussi … (+1 IPMI):
Carte réseau pour les flux métiers (ton traffic web , tes clients etc …),
Carte réseau pour la gestion du cluster (corosync, vmkernel linux ha, heartbeat etc),
Carte réseau pour le système de fichier distribué (sur un « vrai » datacenter moi je plaçais du fiber channel , croisé partout etc ),
Carte réseau pour ton réseau de sauvegarde (tu sauvegardes en journée en pleine prod. , ainsi tu ralentis très peu ton activité … si tes disques -ssd- et ton réseau n°3 (précédent) sont bien dimensionnés
Si on ne respecte pas ce minimum … il y a des soucis de perf. … et ilinux tourne avec des HDD 2To donc on DOIT optimiser, sinon on crève. (on va peut etre crever d’ailleurs lol), avoir monté un datacenter pour un gros ministère ca aide … (bon là tout était fibré)
Note : quand t’es riche tout ces liens sont en fibre à 10Gb mini … (et plus)
Fait de manière minimale cela donne cela (remplace ceph par DRDB):
Et si j’en crois l’archi. de Ganeti … tu as aussi cette problèmatique (en fait tout se ressemble …)