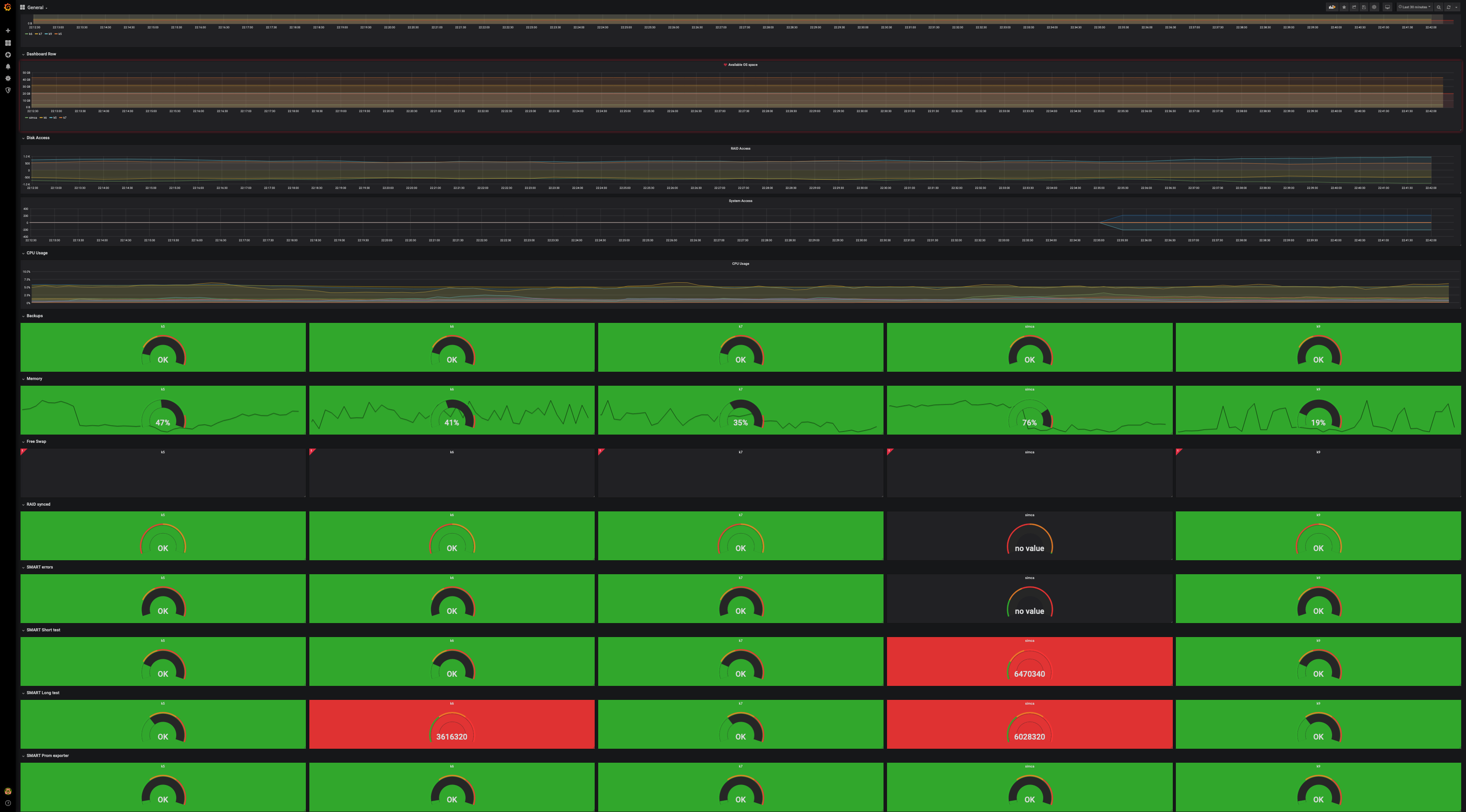
J’utilise smartmontools et son daemon pour surveiller sur chacune de mes machines l’état SMART des disques et lancer régulièrement des tests SMART. En cas d’anomalie il envoie un mail ce qui aujourd’hui m’a permis de détecter un disque défectueux dans une grappe RAID.
Je n’ai pas trouvé d’outil (libre, simple et léger) permettant de surveiller un parc de disques répartis sur plusieurs machines
Je commence à avoir un certain nombre de disques en fonctionnement et comme je compte spécialiser mon futur chaton dans le stockage ça me sera à minima utile voire indispensable.
tu tombes bien!
Jadjay d’alolise m’a glissé à l’oreille que … Grafana avec influxdDB ca marche du feu de dieu : il avait raison !!!
Je suis en train de le mettre en prod pour mon hébergeur. Techniquement ça tournedéjà ici, par contre comme pour toutes supervisions, je dois faire le cahier des charges …
Quoi « monitorer » … et pour mdadm et smart sont CAPITAL)
tu pourrais me contacter pour qu’on envisage , si tu es ok, de se partager les taches pour mettre en place les graphes … et pourquoi pas faire un monitoring croisé … je sais plus ou j’ai lu ca ?
merci pierre.
j’ai pas trop le temps de bûcher grafana, mais ton taf est précieux .
a l’arrache j’ai fait un rapport journalier par mail de mdam, smart, et ceph. plus le démon smart qui crie si un disque est défectueux : donc de base tu as déjà des alertes mail avec /etc/smart.conf.
petite critique sur ton script : évites les while et for.
en système on évites les bloucles : tu peux bloquer une prod. avec une boucle qui deconne.
je posterai mes scripts de backup pour montrer l’idée.
sinon super cool.
par contre tu fais comment pour remonter tout ça dans grafana, tu balances ça dans la de données influxdb ? ou via prometheus ? ( ou dans le script ?)