J’ai remarqué des « scans » (analyse exploratoire) de me serveurs de la part de plein de « boites », dont Stretchoid. J’ai commencé à me poser des questions sur ces gens qui scannent les Internets, à la recherche de failles, ou autre, et qui ne rendent rien en retour.
J’ai remarqué, dans le cas de Stretchoid, que presque toutes leurs requêtes viennent de Digital Ocean, et du coup, j’ai pris le temps de faire un rapport d’abus auprès d’eux. La réponse de Digital Ocean était de me dire que leur client à une page « opt-out » (désabonnement) et ils m’invitent à l’utiliser en rassurant que Stretchoid est réactif.
Est-ce normal de devoir « opt-out » de scans ? Connaissez-vous Stretchoid ? Le site Stretchoid ne contient aucune information sur qu’ils sont, pas de CGU, et la « privacy policy » est du genre « DTC », entre autre, du fait que leur site n’est du tout en https…
Évidement, je doute totalement de la bienveillance de Stretchoid (et consorts) ainsi que l’utilité de « leur laisser faire car ils sont gentils et c’est normal et c’est comme ça la vie ». (au cas ou ce n’était pas claire).
J’aimerais, si possible, avoir d’autres avis, vécus, etc, sur la question avant d’aller plus loin.
Perso j’ai fini par me dire que le scan perpétuel des serveurs faisait partit intégrante du « fonctionnement » d’Internet.
J’ai cherché comment faire pour contribuer à la limitation de ce phénomène à un niveau global, via des services de signalement automatiques par exemple, mais je n’ai rien trouvé de probant.
Je me borne donc à appliquer des mesures locales, sur mes serveurs, en utilisant portsentry par exemple.
J’ai également tenté d’utiliser le mail d’abus de certains hébergeurs, et mes mails sont restés lettre morte.
Je ne connais pas bien la législation étrangère, en France le scan de port est interdit (dites moi si je me trompe), ce n’est peut-être pas le cas ailleurs, d’où la réponse de Digital Ocean ?
Je suis aussi curieux de savoir si des personnes ont un avis/ des lecture sur le sujet. Récemment une machine de Enough a subit durant 15 jours sans discontinuer une attaque brute force sur le port 22. C’est quotidien pour toutes les machines, ce qui était différent dans ce cas c’est l’intensité qui a provoqué des indisponibilités du service par moment. J’ai pensé que c’était un mauvais réglage de l’attaque puisque le deni de service n’est pas l’objectif. Mais ce n’était pas si mal réglé que ça parce que ça n’a pas déclenché les mesures de sécurité d’OVH, le fournisseur sur lequel repose la VM.
Bref, j’ai tendance a penser que c’est la vie, même si c’est un peu triste de devoir entourer les machines de miradors et de murs en béton au lieu de les laisser gambader dans les prés.
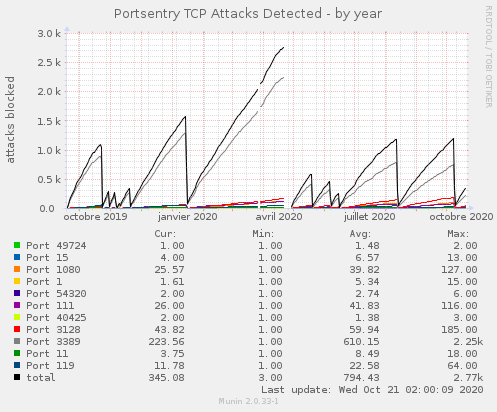
Perso j’ai mis portsentry, c’est des « faux » port en écoute et 1 connexion = bloqué dans le firewall… c’est plutôt efficace (en plus en écoute sur le 22) :
Ca interpelle les tentatives sur les ports 54320 et 49724. Il y a sûrement une histoire palpitante qui explique pourquoi ils sont intéressants. Ou une histoire triste de bot égaré dans les ports.
Tu peux détaillés ? Dans mon graph il n’y a que le 1er port scanné parce que le suivant la personne est bloqué sur tout les ports par le firewall… donc oui ce n’est pas le reflet de la réalité d’autant que ça doit beaucoup dépendre des serveurs… c’est ma réalité.
C’est une erreur de ma part.
Effectivement il semblerai que Portsentry bloque dès la connexion à un port et n’attend pas que plusieurs connexions à des ports différents aient lieux.
J’ai eu la même mais sur 2 jours. Le brute force est quelque chose de perpetuel sur SSH mais mon service ssh est tombé (c’était une première) et ça a aussi dégradé d’autres services (imap et http).
323-1: « Le fait d’accéder ou de se maintenir… » donc un scan de port n’y entre pas, et même un brute-force SSH n’est pas couvert par cet article !
323-2: « Le fait d’entraver ou de fausser le fonctionnement » donc là c’est plus de DOS qui est visé
323-3: « Le fait d’introduire frauduleusement des données »
323-4: « La participation à un groupement formé ou à une entente établie en vue de la préparation, caractérisée par un ou plusieurs faits matériels, d’une ou de plusieurs des infractions prévues par les articles 323-1 à 323-3-1 » là ça couvre en plus indirectement le DDOS…
Voilà, si quelqu’un trouve d’autres textes réglementaires, je suis preneur !
Une attaque brute-force, sans autorisation, sur SSH ou HTTPS, si elle réussit, peut facilement être considérée comme un accès frauduleux… Enfin moi je le lis comme ça, et à moins qu’on me présente des jurisprudences qui expliquent le contraire, je ne comprend pas comment on pourrait lire ça autrement.
Pour les scans, il y a l’article sur les équipements aussi:
Le fait, sans motif légitime, notamment de recherche ou de sécurité informatique, d’importer, de détenir, d’offrir, de céder ou de mettre à disposition un équipement, un instrument, un programme informatique ou toute donnée conçus ou spécialement adaptés pour commettre une ou plusieurs des infractions prévues par les articles 323-1 à 323-3 est puni des peines prévues respectivement pour l’infraction elle-même ou pour l’infraction la plus sévèrement réprimée.
C’est sur cet article que porte le débat de ce topic. La question ici est de savoir si stretchoid utilise les résultats des scans qu’ils détient dans un but de recherche ou de sécurité informatique (et aussi de savoir si stretchoid tombe sous la juridiction française ou autre sur ce sujet).
Et clairement, dans cet article, on sent bien toute l’ambivalence qui existe à ce sujet dans le domaine de « la sécurité informatique ». Car pour sécuriser les systèmes informatiques, il faut anticiper les risques, les attaques possibles… Donc faire de la recherche, comprendre/cartographier/recenser les failles les plus probables, avertir, etc.
C’est vrai qu’on peut utiliser des résultats de scan sans les détenir sur le long terme. A mon avis, la portée de ce détenir pourrait justement faire l’objet d’extrapolation de la part d’un juge, avoir une lecture juridique implique de connaître la jurisprudence associée et tout un tas d’autres textes ou certaines notions peuvent avoir été précisées (en tout cas c’est l’aperçut que j’avais eu des discussions dans le feu groupe « no log » de la FFDN (constitué à l’époque de juristes).
Une lecture juridique, ce n’est pas la lecture d’un code source. Sans compter que certains mots peuvent désigner tout autre chose que le même mot dans le domaine de l’informatique.
Stretchoid ne propose aucune information la dessus. Sur leur page en HTTP, il n’y a rien d’autre qu’un formulaire de « opt-out ». Aucun CGU, pas de politique de confidentialité, pas de « qui sommes nous », même pas une page contact, rien.
Je pense répondre à Digital Ocean que leur réponse n’est pas très lol, au moins pour la forme.
Je ne pense pas être le seul à avoir utilisé nmap pour identifier un service, un os. Ou alors, vous êtes des sacrés enfumeurs.
La base d’empreinte qui permet à nmap de faire cela est communautaire. Vous pouvez y contribuer lorsque vous avez identiifié une empreinte. C’est ici. Ya du taf si on considère tout ce qui se connecte.
Du coup, on peut dire que sans le vouloir vous avez peut être utilisé un outil même pas forensic mais complétement construit à partir de multiple scan de port effectué par toute une communauté de personnes par forcément malintentionnées… Mais potentiellement les mêmes qui pourrissent vos logs, à l’instar de stretchoid.
Sur le plan législatif, comme le rappelait très justement @cquest, les articles du code pénal concernant le break d’un système d’information sont juste comme il faut. Et on va pas s’en plaindre. Il y a quand même des gens qui se sont retrouvés en taule après avoir posé leur drapeau, puis gentiment signalé le bug. Alors, imaginez si la législation était durcie.
Il y a des juges et des entreprises qui n’ont pas d’humour
Merci pour ton point de vue, c’est très bien vue. J’ai ouvert ce fil justement pour cela, pour tourner le problème dans différents sens.
Je me dis qu’on peut aussi parler de netiquette, disons qu’un scan, pour la science, en produisant des jolies cartes et autres jeu de données, disponibles pour tout les humains, pourquoi pas.
Aussi, les entreprises comme Stretchoid, Censys, ReportItHere, Websec-Test, Internettl et d’autres que je découvre, ne semble pas être dans ces sphères. Ils ont souvent des pages web qui ne disent pas grand choses et parfois propose un opt-out, souvent via des pages non-https.