je suis en train de maqueter sous proxomox et CEPH pour un système de fichier distribué (d’ailleurs je me posais la question de CEPH ou GlusterFS pour des perf. acceptables ?).
C’est prometteur.
Cela tourne mais je n’arrive pas à comprendre la tolérance de panne exact qu’offre cette solution, je maitrise le RAID mais là … c’est nouveau !
je suis configuré ainsi :
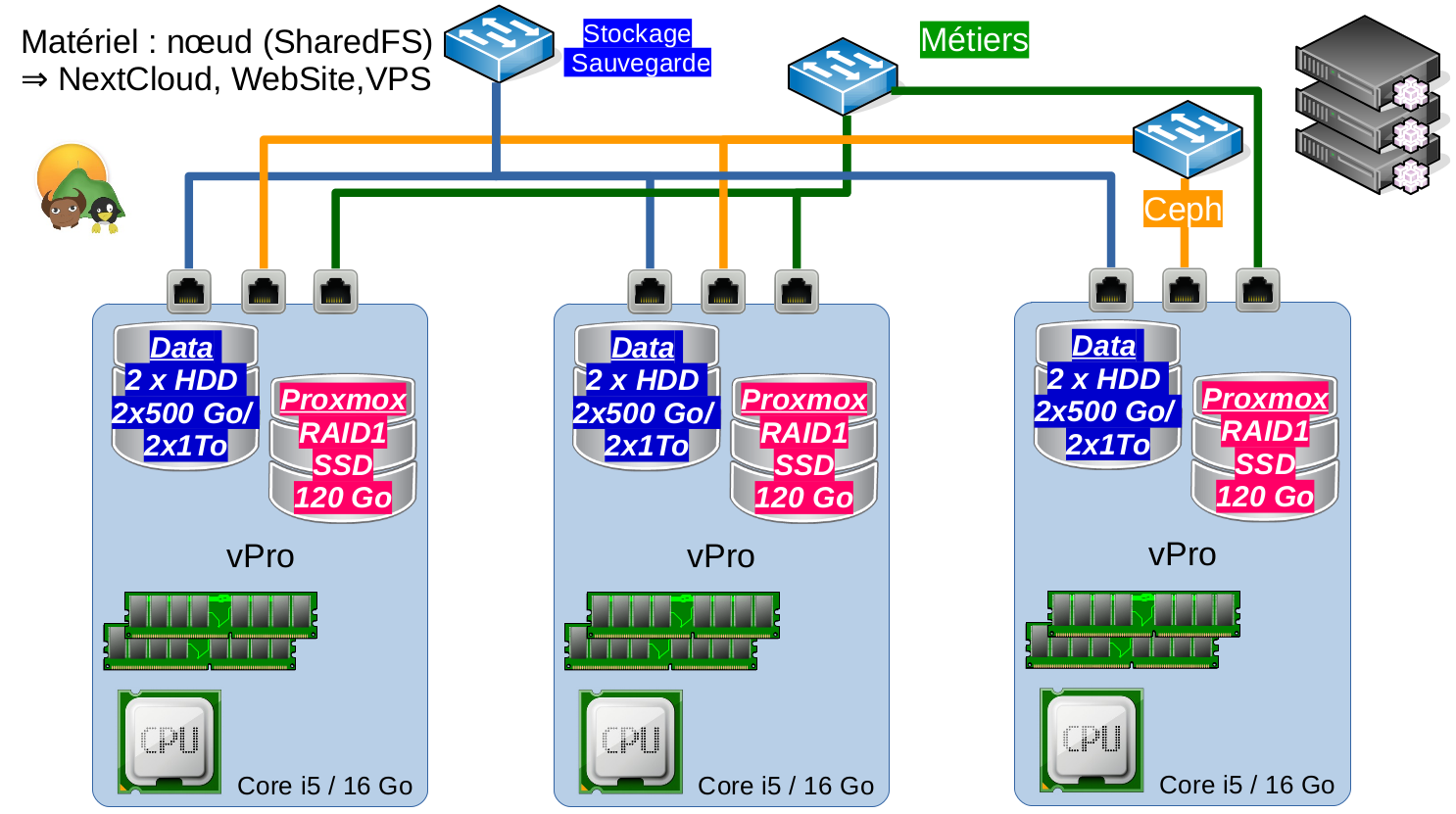
3 noeuds proxmox :
core i5,
16 Go,
2xSSD 120Go en raid1 pour proxmox (3 periph /dev/md0, 1 et 2) et les templates voir iso,
2x 500Go HDD … pour les osd.
3 carte reseau par noeuds (un réseau pour les flux métiers, un réseau pour les OSD, un réseau … le backup a voir)
le tout en cluster, 3 moniteurs un par noeuds, 2 osd par noeuds …
ca marche mais je comprends pas la tolérance de panne etc …
La fonction du cluster (stockage - équilibrage de charge - continuité de service) est à installer afin de constituer une grappe de nœuds physiques. Exemple :
BASE : Nœud physique A avec 4 VM serveur web / 1 Nœud physique B avec 4 VM serveur web / Nœud physique C avec 4 VM serveur web
Si tu as configuré la fonction continuité de service sur ton cluster, si le Proxmox A tombe, la redondance se fera sans perte de service sur les serveurs B et C
J’arrive après la bataille, mais après utilisé Ceph sur un petit cluster proxmox de 3 noeuds, nous avons complètement arrêté car les perfs étaient très mauvaises.
Il faut soit un réseau très rapide (du gigabit ne suffit pas vraiment), soit limiter uniquement ceph au stockage d’archives et de backups ou stockage objet (type S3, swift).
Sous proxmox j’utilise désormais ZFS qui apporte:
snapshots et clones (snapshot qu’on repasse en read/write)
compression
déduplication (si on a de la RAM)
les send/receive (génial !)
Du coup pour promox et les VM/CT cela permet:
la réplication (très rapide, basé sur les send/receive)
les snapshots
la migration quasi instantanée des VM/CT, et en bonus la haute dispo
ZFS est très robuste, conçu dans cette optique. Autre avantage, un mix HDD + SSD permet d’utiliser les SSD en cache de façon transparente.
Mon futur chaton sera basé sur un cluster de 3 serveurs sous proxmox et ZFS comme stockage principal.
Salut @cquest
Merci de ce retour. On utilise Ceph chez Frama, et notre bien-aimé adminsys semblait plutôt content de Ceph, mais on l’utilise effectivement pour du stockage objet il me semble. Et il me semble que le cluster tombe assez régulièrement. Bref, ça semble aller dans ton sens.
Merci pour ce retour d’expérience.
Mais … ma prod. est maintenant montée avec du ceph ET des cartes réseaux en gigabit.
Ensuite tu parles de ZFS , le truc pour qui il faut 1Go de RAM par To de data ?
Désolé je ne suis pas assez riche … mes noeuds n’ont « que » 16Go de RAM …
Ensuite je ne vois pas comment Ceph (mais la encore je verrai bien) peut ramer alors que mes disques (OSD) durs sont des plateaux qui crachent à peine du 60Mo/s … mon réseau dédié pouvant sortir du 120Mo /s … par carte avec un switch totalement dédié à Ceph.
Mais tu a peut etre bien raison : on verra bien.
ZFS a besoin de RAM essentiellement pour la déduplication.
Ce retour d’expérience provient du cluster mis en place pour OSM France.
On avait un lien gigabit séparé, disques mécaniques (1 HDD sur chacun des 3 noeuds du cluster), stockage des containers LXC sur ceph.
Il y avait bien trop de traffic réseau, des latences bien trop importantes (le débit n’est pas le seul élément à prendre en compte)… et énormément d’I/O sur les disques (saturés à 100% en quasi permanence).
On a rebasculé dans un premier temps en stockage local, puis remplacé ceph par un pool ZFS sur chaque noeud et remis les containers sur ZFS et ça va beaucoup mieux depuis.
La copie/synchro des containers prends quelques secondes chaque 15mn et c’est suffisant en terme de sécurité des données pour notre cas.
Ces serveurs sont relativement chargés, les soucis peuvent n’apparaitre qu’à partir d’une certaine charge en I/O.
… ah ok : ceph + corosync sur le meme port réseau , bahhhhhhhhhhhhhhhhhhhhhhhhhh
Sans vouloir faire mon kikou, mélanger le heartbeat du cluster et du flux stockage : meme pas peur ?
Question : tu as regardé mon schém au-dessu , pour le cablage hardware ?
C’est la base quand on monte un cluster … on sépare les flux: stockage, métier ET de la gestion cluster.
chez vmware c le vmkernel, chez proxmox le corsyng , il ya heartbeat , hasuite sur as400 etc etc …
Ne pas mélanger les éfluves.
Mais bon je ne suis pas ecnore monté en charge donc je m’écrase.
Je garde ZFS en option au cas ou : mais ZFs fait du distribué sur le cluster ?
Les serveurs dédiés loués ont rarement plus de 2 ports réseau, là où il en faudrait 3 ou 4 (avec bonding là où c’est utile). Sûr que ça a dû impacter nos perf.
donc game over pour toi.
je comprend pourquoi les perfs étaient perraves, ton cluster devait devenir dingue et perdre les pédales.
Mais soyons humble peut etre me gourre-je
En tout cas merci de vos experiences, je vous ferrai part de la mienne .
bien après la bataille aussi On utilise ceph aussi, et très content pour le moment.
Très robuste, on a eu plusieurs galère, mais on a jamais rien perdu, et le cluster était toujours utilisable, sauf une fois, avec 1 petite heure de down.
En gros, on a 3 hosts et chaque host avec 2 NVMe et 2 HDD 10TB. Et 2 cartes réseaux, 1GB et 10GB.
Ca se passe bien Si vous avez des soucis, n’hesitez pas a nous pinguer.
par contre on est moins riche …
noeuds x 3:2x SSD 120 go en raid1 mdadm, 2 x 2to hdd … 3 cartes intel 1 gb (backup, métiers, ceph ) : corosync sur backup mais c’est pas trop gênant car 99% des backup passe en 2 à 40 secondes … pour l’instant (seul un CT de 200go met 58mn … et je ne sais pas pourquoi)
on est en 3/2 : 3 copie des datas … donc sur nos 12 to, 4 to exploitable
l’idéale c 4 cartes réseaux , avec 2 tu vas avoir des merdes niveau corosync quand tu vas avoir une montée en charge sur le lien 1gb.(métiers je suppose ?), 10gb pour ceph … c’est riche, si tu as du disque plateau. Mais bon tu pourras voir venir.


 )
)