Durée estimée : une demi journée
Pré-requis : nécessite une connaissance de Linux, de git et de la ligne de commande (coreutils)
Licence : CC0
Ce n’est pas une doc exhaustive, vous trouverez des infos plus complètes+précises ici :
- devinsy/statoolinfos: StatoolInfos is a simple project of statistics about federation, organizations and services. - statoolinfos - La forge Devinsy
- CHATONS / ChatonsInfos · GitLab
Commencez par télécharger l’outil qui nous permettra de valider nos fiches.
- Allez sur devinsy/statoolinfos: StatoolInfos is a simple project of statistics about federation, organizations and services. - statoolinfos - La forge Devinsy
- Onglet Versions
- Actuellement, la dernière version en date est la « pré-publication » Snapshot 0.5.1-d
- Téléchargez le fichier
statoolinfos.jarde cette version
Une fois téléchargé, vérifiez qu’il fonctionne bien :
java -jar statoolinfos.jar
No parameter.
StatoolInfos CLI version 0.5.1-20220627220034
Usage:
statoolinfos [ -h | -help | --help ]
statoolinfos [ -v | -version | --version ]
...
Ensuite notre outil a besoin d’un fichier de base qui va lui indiquer qui crawler.
Nous, on va en créer un fake à partir du fichier original CHATONS.
Pour ça, on va en profiter pour cloner le repo chatonsinfos (ça va nous servir plus tard) :
git clone git@framagit.org:chatons/chatonsinfos.git
cd chatonsinfos
Ensuite on va créer une version simplifiée du « fichier de configuration » de crawl où l’on va enlever tous les participants actuels :
cd StatoolInfos
grep -vP '^subs\.' chatons.properties > only-me.properties
Et on va rajouter notre future URL, vous pouvez choisir l’URL que vous voulez tant que vous serez en mesure d’y mettre un fichier texte au bout. Les devs de l’outil recommandent d’utiliser /.well-known/chatonsinfos. Si vous êtes flexibles dans les URLs que vous pouvez mettre, je vous recommande de vous calquer sur libre-service.eu, le CHATONS d’un des dev :
https://www.libre-service.eu/.well-known/chatonsinfos/libre-service.eu.properties
On ajoute notre ligne à la fin du fichier
echo 'subs.deuxfleurs=https://deuxfleurs.fr/.well-known/chatonsinfos/deuxfleurs.fr.properties' >> only-me.properties
On va créer un fichier de crawl basique ensuite nommé crawl.conf :
conf.class=federation
conf.protocol=StatoolInfos-0.5.0
conf.crawl.input=http://127.0.0.1:8000/only-me.properties
conf.crawl.cache=/tmp/crawl
conf.htmlize.categories=./categories/categories.properties
conf.htmlize.input=http://127.0.0.1:8000/only-me.properties
conf.htmlize.directory=.
Comme vous le constatez, on doit exposer le fichier only-me via du HTTP et on besoin d’un cache de crawl. Commencez par créer le dossier pour le crawl. Ensuite ouvrez donc un autre terminal dans le dossier qui contient votre fichier
only-me.properties et lancez un serveur web que vous garderez allumer tout le temps de ce tuto :
mkdir -p /tmp/crawl
python3 -m http.server
Maintenant vous êtes fin prêt-e à faire planter l’outils en le lançant une première fois !
java -jar statoolinfos.jar crawl ./crawl.conf
Et vous devriez obtenir la sortie suivante :
Crawl cache setting: /tmp
Crawling http://127.0.0.1:8000/only-me.properties
Crawling https://framagit.org/chatons/CHATONS/-/raw/master/docs/communication/logo/logo_chatons_v3.1.png
Crawling https://deuxfleurs.fr/.well-known/chatonsinfos/deuxfleurs.fr.properties
ERROR: crawl failed for [https://deuxfleurs.fr/.well-known/chatonsinfos/deuxfleurs.fr.properties]: https://deuxfleurs.fr/.well-known/chatonsinfos/deuxfleurs.fr.properties
Storing crawl journal.
00:00:01
Excellent ! On a une erreur sur le lien, mais c’est normal : notre fichier n’existe pas encore ! On va donc le créer. Pour cela, on va se baser sur les modèles fournis dans le git CHATONS.
À noter que les ressources suivantes sont intéressantes aussi pour vérifier ce qu’on fait :
- L’ontologie par les maintainers du projet
- La fiche de libreservice.eu, CHATON maintainer
- La fiche de nomagic.uk, très complète
- Framasoft, parce qu’on les aime
Bon donc je commence par télécharger le modèle d’organisation :
wget \
-O deuxfleurs.fr.properties \
https://framagit.org/chatons/chatonsinfos/-/raw/master/MODELES/organization.properties?inline=false
Je l’édite avec vim et je remplis chaque champs à la main.
Notes : les formats de date ne sont pas stables à travers le fichier: une fois c’est le format ISO, une fois le format français. Faites attention donc, l’outil est rigide dans ce qu’il accepte.
Vu que ce fichier sera crawlé régulièrement, on peut viser une petite optimisation et supprimer les commentaires et lignes vides:
sed -i '/^#/d' ./deuxfleurs.fr.properties
sed -i '/^$/d' ./deuxfleurs.fr.properties
Ensuite, il ne reste plus qu’à publier le fichier sur votre site web à l’URL indiquée précédemment !
Une fois l’opération réalisée, on peut relancer statoolinfos pour voir si il est content :
$ java -jar statoolinfos.jar crawl ./crawl.conf
Crawl cache setting: /tmp
Crawling http://127.0.0.1:8000/only-me.properties
Crawling https://framagit.org/chatons/CHATONS/-/raw/master/docs/communication/logo/logo_chatons_v3.1.png
Crawling https://deuxfleurs.fr/.well-known/chatonsinfos/deuxfleurs.fr.properties
Crawling https://deuxfleurs.fr/.well-known/chatonsinfos/deuxfleurs.svg
Storing crawl journal.
00:00:01
Super, notre organisation lui plaît bien.
Mais statoolinfos ne sait toujours rien de nos services 
On va donc ajouter des fichiers de dépendances à notre fichier organisation.
Ici, tous nos fichiers de dépendances seront des « services ».
Le dossier MODELES a des fichiers de services déjà configuré pour certains logiciels comme Jitsi que vous pouvez réutiliser pour gagner un peu de temps. Sinon tout en bas, vous avez un modèle de service vierge.
Note : le schéma du README ne correspond pas au modèle Jitsi donné. Dans le schéma, hosting dépend d’organization directement, alors que dans le modèle il dépend du service. On verra par la suite que hosting est bien lié à un service et que donc le modèle est juste et le schéma est faux.
On n’oublie pas d’enlever les commentaires et lignes blanches :
sed -i '/^#/d' ./jitsi.properties
sed -i '/^$/d' ./jitsi.properties
Ensuite on peut référencer notre fichier Jitsi dans notre fichier organisation :
echo 'subs.jitsi = https://deuxfleurs.fr/.well-known/chatonsinfos/jitsi.properties' >> deuxfleurs.fr.properties
Republiez tous ces fichiers sur votre site, et vérifiez que le crawler les récupère bien :
$ java -jar statoolinfos.jar crawl ./crawl.conf
Crawl cache setting: /tmp
Crawling http://127.0.0.1:8000/only-me.properties
Crawling https://framagit.org/chatons/CHATONS/-/raw/master/docs/communication/logo/logo_chatons_v3.1.png
Crawling https://deuxfleurs.fr/.well-known/chatonsinfos/deuxfleurs.fr.properties
Crawling https://deuxfleurs.fr/.well-known/chatonsinfos/deuxfleurs.svg
Crawling https://deuxfleurs.fr/.well-known/chatonsinfos/jitsi.properties
Crawling https://deuxfleurs.fr/.well-known/chatonsinfos/deuxfleurs.svg
Storing crawl journal.
00:00:01
Voilà, vous pouvez de manière itérative appliquer cette méthode pour tous vos autres services.
Si vous craignez d’oublier un de vos services, allez donc voir votre fiche CHATONS sur le site chatons.org x)
On peut maintenant essayer de générer le site web :
java -jar statoolinfos.jar crawl ./crawl.conf
java -jar statoolinfos.jar htmlize ./crawl.conf
Puis ouvrez le fichier index.html dans Firefox.

Vous pouvez voir les checks qui ne passent pas.
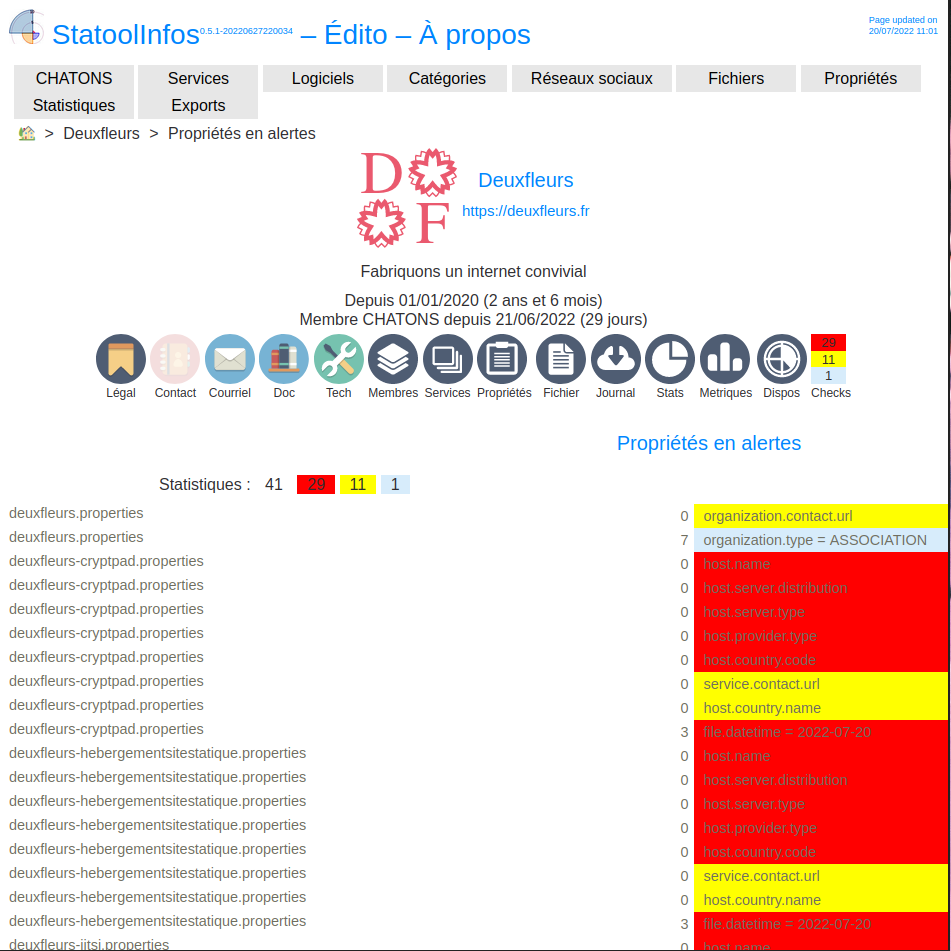
Par exemple, dans mon cas on note que :
- malgré ce que dit le modèle, la valeur
ASSOCIATIONn’est pas supportée pourorganization.type. En réalité c’est même la propriétéorganization.typecomplète qui n’existe pas du tout. - des valeurs comme
organization.contact.urlsont obligatoires alors qu’on a pas d’URL spécifique - il est obligé de préciser le host dans les fichiers de services, on a donc notre réponse à notre interogation précédente : c’est le modèle qui est correct et le schéma du README qui est faux.
- pour le
file.datetimeon peut pas mettre juste une date ISO, on doit mettre une heure aussi.
N’oublions pas que « Code is law » : il est tentant de plier nos pratiques pour satisfaire ĺ’outil et donc se soumettre à sa loi. Pourtant l’outil n’est pas neutre, il est créé par des humains avec certaines suppositions et biais. Il y a une raison pour laquelle on a pas d’URL de support : on intéragit directement avec nos membres et on veut garder une page unique, on ne créera donc pas de page spécifique même si on nous le demande. Après rien n’interdit de donner des valeurs pour satisfaire l’outil.
Une fois vos modifications réalisées, publiez le sur votre site web et relancez ET le crawl ET la génération HTML :
java -jar statoolinfos.jar crawl ./crawl.conf
java -jar statoolinfos.jar htmlize ./crawl.conf
Si tout se passe bien, vos fichiers ne généreront aucune erreur :

Vous êtes prêt-e à ouvrir une merge request sur Gitlab.
Forkez le dépot ChatonsInfos : CHATONS / ChatonsInfos · GitLab
Ensuite dans votre dépôt git actuel, ajoutez votre fork et créez une nouvelle branche :
git remote add fork git@framagit.org:superboum1/chatonsinfos.git
git checkout -b ajout_deuxfleurs
Maintenant, ajouter votre ligne sub.xxx du fichier only-me.properties au fichier chatons.properties. Il semble que les maintainers souhaitent garder la liste ordonnée alphabétiquement. Ouvrez le fichier et rajoutez donc votre ligne au bon endroit. Exemple avec ma ligne :
subs.deuxfleurs=https://deuxfleurs.fr/.well-known/chatonsinfos/deuxfleurs.fr.properties
Ne commitez que ce fichier chatons.properties et pushez sur votre fork :
git push fork
Quelques liens pour terminer :
- Vous pouvez consulter ma MR ici : Ajout du CHATON deuxfleurs.fr (!47) · Merge requests · CHATONS / ChatonsInfos · GitLab
- Nos fichiers se trouvent ici : Deuxfleurs/site: deuxfleurs.fr - site - Gitea: git with a cup of coffee
Ouf nous voilà à la fin. C’était assez fastidieux de remplir les fichiers car je me retrouve à répéter certaines valeurs 5 ou 6 fois. Avoir plus de valeurs optionnelles et déduire les valeurs manquantes pourrait être un vrai plus. Par exemple on a qu’une seule page de mention légale, référencée dans Organisation. Si je ne la référence pas dans un service, l’outil pourrait deviner tout seul qu’il doit prendre celle de l’organisation. Pareil pour l’email de contact et bien d’autres éléments. Il y aussi plein de champs obligatoires dont je ne comprends pas le but, et qui parfois me semblent ne pas être en mesure de représenter notre réalité. En tout cas, j’ai quand même réussi à arriver au bout, donc rien de trop bloquant, à votre tour maintenant  !
!
Voilà, je ne fais pas parti du projet, ce tutoriel n’est en réalité que mes notes de ce matin. Je laisse les maintainers préciser si besoin.